刷题刷出新高度,偷偷领先!偷偷领先!偷偷领先! 关注我们,悄悄成为最优秀的自己!
面试题
HBase 的特点是什么
使用微信搜索喵呜刷题,轻松应对面试!
答案:
分析&回答
HBase 基本特点
- HBase是一个分布式的、面向列的开源数据库存储系统,具有高可靠性、高性能和可伸缩性,它可以处理分布在数千台通用服务器上的PB级的海量数据。
- HBase不同于一般的关系型数据库,它是一个适合于非结构化数据存储的数据库。HBase不限制存储的数据的种类,允许动态的、灵活的数据模型。
- BigTable的底层是通过GFS来存储数据,而HBase对应的则是通过HDFS(Hadoop分布式文件系统)来存储数据的。
- hbase是主从架构。hmaster作为主节点,hregionserver作为从节点。
- 基于的表包含rowkey,时间戳,和列族。新写入数据时,时间戳更新,同时可以查询到以前的版本.
- Hbase为null的记录不会被存储.
- 多版本号数据,依据Row key和Column key定位到的Value能够有随意数量的版本号值,因此对于须要存储变动历史记录的数据,用HBase是很方便的。比方某个用户的Address变更,用户的Address变更记录也许也是具有研究意义的。
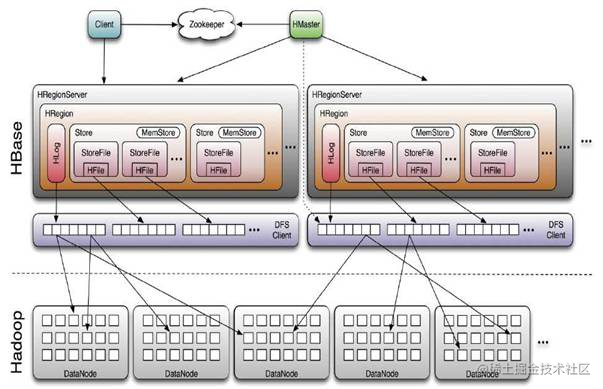
HBase 系统架构图
HBase 数据模型

组成部件说明:
- Row Key: Table主键 行键 Table中记录按照Row Key排序
- Timestamp: 每次对数据操作对应的时间戳,也即数据的version number
- Column Family: 列簇,一个table在水平方向有一个或者多个列簇,列簇可由任意多个Column组成,列簇支持动态扩展,无须预定义数量及类型,二进制存储,用户需自行进行类型转换
Table&Region
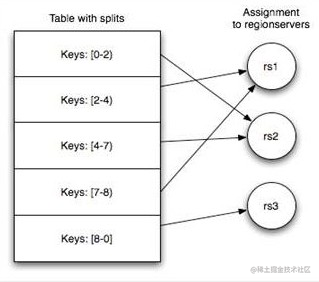
- Table随着记录增多不断变大,会自动分裂成多份Splits,成为Regions
- 一个region由[startkey,endkey)表示
- 不同region会被Master分配给相应的RegionServer进行管理
两张特殊表:-ROOT- & .META.
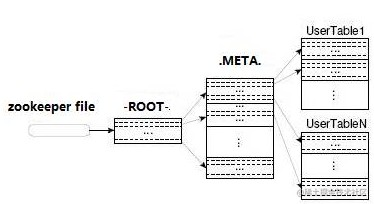
- .META. 记录用户表的Region信息,同时,.META.也可以有多个region
- -ROOT- 记录.META.表的Region信息,但是,-ROOT-只有一个region
- Zookeeper中记录了-ROOT-表的location
- 客户端访问数据的流程:
- Client -> Zookeeper -> -ROOT- -> .META. -> 用户数据表
- 多次网络操作,不过client端有cache缓存
反思&扩展
HBase与传统关系型数据库(如MySQL)的区别
- 数据类型:没有数据类型,都是字节数组(有一个工具类Bytes,将java对象序列化为字节数组)。
- 数据操作:HBase只有很简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系,而传统数据库通常有各式各样的函数和连接操作。
- 存储模式:Hbase适合于非结构化数据存储,基于列存储而不是行。
- 数据维护:HBase的更新操作不应该叫更新,它实际上是插入了新的数据,而传统数据库是替换修改
- 时间版本:Hbase数据写入cell时,还会附带时间戳,默认为数据写入时RegionServer的时间,但是也可以指定一个不同的时间。数据可以有多个版本。
- 可伸缩性,Hbase这类分布式数据库就是为了这个目的而开发出来的,所以它能够轻松增加或减少硬件的数量,并且对错误的兼容性比较高。而传统数据库通常需要增加中间层才能实现类似的功能
创作类型:
原创
本文链接:HBase 的特点是什么
版权声明:本站点所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明文章出处。让学习像火箭一样快速,微信扫码,获取考试解析、体验刷题服务,开启你的学习加速器!

分享考题 


